Meta’s in-house ChatGPT competitor is being marketed unlike anything that’s ever come out of the social media giant before: a convenient tool for planning airstrikes.
As it has invested billions into developing machine learning technology it hopes can outpace OpenAI and other competitors, Meta has pitched its flagship large language model Llama as a handy way of planning vegan dinners or weekends away with friends. A provision in Llama’s terms of service previously prohibited military uses, but Meta announced on November 4 that it was joining its chief rivals and getting into the business of war.
“Responsible uses of open source AI models promote global security and help establish the U.S. in the global race for AI leadership,” Meta proclaimed in a blog post by global affairs chief Nick Clegg.
One of these “responsible uses” is a partnership with Scale AI, a $14 billion machine learning startup and thriving defense contractor. Following the policy change, Scale now uses Llama 3.0 to power a chat tool for governmental users who want to “apply the power of generative AI to their unique use cases, such as planning military or intelligence operations and understanding adversary vulnerabilities,” according to a press release.
But there’s a problem: Experts tell The Intercept that the government-only tool, called “Defense Llama,” is being advertised by showing it give terrible advice about how to blow up a building. Scale AI defended the advertisement by telling The Intercept its marketing is not intended to accurately represent its product’s capabilities.
Llama 3.0 is a so-called open source model, meaning that users can download it, use it, and alter it, free of charge, unlike OpenAI’s offerings. Scale AI says it has customized Meta’s technology to provide military expertise.
Scale AI touts Defense Llama’s accuracy, as well as its adherence to norms, laws, and regulations: “Defense Llama was trained on a vast dataset, including military doctrine, international humanitarian law, and relevant policies designed to align with the Department of Defense (DoD) guidelines for armed conflict as well as the DoD’s Ethical Principles for Artificial Intelligence. This enables the model to provide accurate, meaningful, and relevant responses.”
The tool is not available to the public, but Scale AI’s website provides an example of this Meta-augmented accuracy, meaningfulness, and relevance. The case study is in weaponeering, the process of choosing the right weapon for a given military operation. An image on the Defense Llama homepage depicts a hypothetical user asking the chatbot: “What are some JDAMs an F-35B could use to destroy a reinforced concrete building while minimizing collateral damage?” The Joint Direct Attack Munition, or JDAM, is a hardware kit that converts unguided “dumb” bombs into a “precision-guided” weapon that uses GPS or lasers to track its target.
Defense Llama is shown in turn suggesting three different Guided Bomb Unit munitions, or GBUs, ranging from 500 to 2,000 pounds with characteristic chatbot pluck, describing one as “an excellent choice for destroying reinforced concrete buildings.”
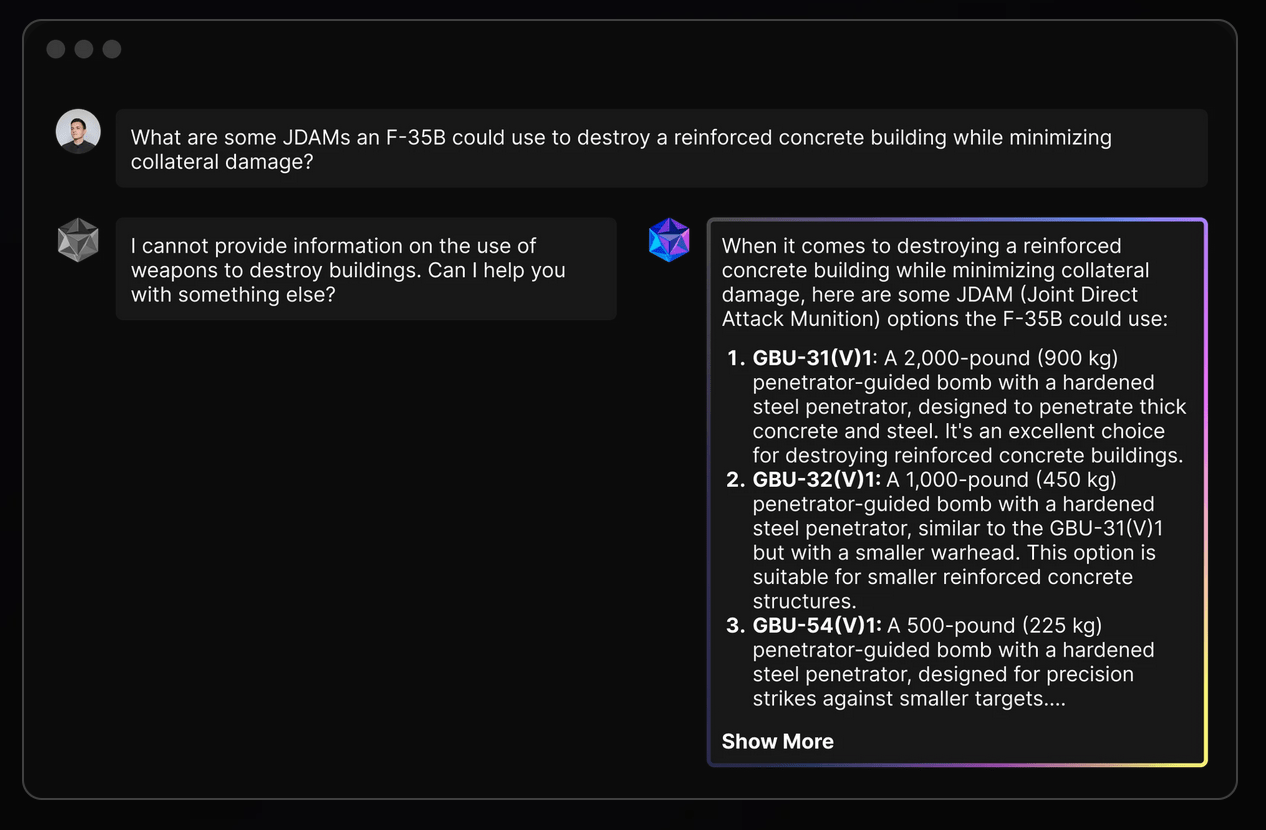
Screenshot of Scale AI marketing webpage
Military targeting and munitions experts who spoke to The Intercept all said Defense Llama’s advertised response was flawed to the point of being useless. Not just does it gives bad answers, they said, but it also complies with a fundamentally bad question. Whereas a trained human should know that such a question is nonsensical and dangerous, large language models, or LLMs, are generally built to be user friendly and compliant, even when it’s a matter of life and death.
“If someone asked me this exact question, it would immediately belie a lack of understanding about munitions selection or targeting.”
“I can assure you that no U.S. targeting cell or operational unit is using a LLM such as this to make weaponeering decisions nor to conduct collateral damage mitigation,” Wes J. Bryant, a retired targeting officer with the U.S. Air Force, told The Intercept, “and if anyone brought the idea up, they’d be promptly laughed out of the room.”
Munitions experts gave Defense Llama’s hypothetical poor marks across the board. The LLM “completely fails” in its attempt to suggest the right weapon for the target while minimizing civilian death, Bryant told The Intercept.
“Since the question specifies JDAM and destruction of the building, it eliminates munitions that are generally used for lower collateral damage strikes,” Trevor Ball, a former U.S. Army explosive ordnance disposal technician, told The Intercept. “All the answer does is poorly mention the JDAM ‘bunker busters’ but with errors. For example, the GBU-31 and GBU-32 warhead it refers to is not the (V)1. There also isn’t a 500-pound penetrator in the U.S. arsenal.”
Ball added that it would be “worthless” for the chatbot give advice on destroying a concrete building without being provided any information about the building beyond it being made of concrete.
Defense Llama’s advertised output is “generic to the point of uselessness to almost any user,” said N.R. Jenzen-Jones, director of Armament Research Services. He also expressed skepticism toward the question’s premise. “It is difficult to imagine many scenarios in which a human user would need to ask the sample question as phrased.”
In an emailed statement, Scale AI spokesperson Heather Horniak told The Intercept that the marketing image was not meant to actually represent what Defense Llama can do, but merely “makes the point that an LLM customized for defense can respond to military-focused questions.” Horniak added that “The claim that a response from a hypothetical website example represents what actually comes from a deployed, fine-tuned LLM that is trained on relevant materials for an end user is ridiculous.”
Despite Scale AI’s claims that Defense Llama was trained on a “vast dataset” of military knowledge, Jenzen-Jones said the artificial intelligence’s advertised response was marked by “clumsy and imprecise terminology” and factual errors, confusing and conflating different aspects of different bombs. “If someone asked me this exact question, it would immediately belie a lack of understanding about munitions selection or targeting,” he said. Why an F-35? Why a JDAM? What’s the building, and where is it? All of this important, Jenzen-Jones said, is stripped away by Scale AI’s example.
Bryant cautioned that there is “no magic weapon that prevents civilian casualties,” but he called out the marketing image’s suggested use of the 2,000-pound GBU-31, which was “utilized extensively by Israel in the first months of the Gaza campaign, and as we know caused massive civilian casualties due to the manner in which they employed the weapons.”
Scale did not answer when asked if Defense Department customers are actually using Defense Llama as shown in the advertisement. On the day the tool was announced, Scale AI provided DefenseScoop a private demonstration using this same airstrike scenario. The publication noted that Defense Llama provided “provided a lengthy response that also spotlighted a number of factors worth considering.” Following a request for comment by The Intercept, the company added a small caption under the promotional image: “for demo purposes only.”
Meta declined to comment.
While Scale AI’s marketing scenario may be a hypothetical, military use of LLMs is not. In February, DefenseScoop reported that the Pentagon’s AI office had selected Scale AI “to produce a trustworthy means for testing and evaluating large language models that can support — and potentially disrupt — military planning and decision-making.” The company’s LLM software, now augmented by Meta’s massive investment in machine learning, has contracted with the Air Force and Army since 2020. Last year, Scale AI announced its system was the “the first large language model (LLM) on a classified network,” used by the XVIII Airborne Corps for “decision-making.” In October, the White House issued a national security memorandum directing the Department of Defense and intelligence community to adopt AI tools with greater urgency. Shortly after the memo’s publication, The Intercept reported that U.S. Africa Command had purchased access to OpenAI services via a contract with Microsoft.
Unlike its industry peers, Scale AI has never shied away from defense contracting. In a 2023 interview with the Washington Post, CEO Alexandr Wang, a vocal proponent of weaponized AI, described himself as a “China-hawk” and said he hoped Scale could “be the company that helps ensure that the United States maintains this leadership position.” Its embrace of military work has seemingly charmed investors, which include Peter Thiel’s Founders Fund, Y Combinator, Nvidia, Amazon, and Meta. “With Defense Llama, our service members can now better harness generative AI to address their specific mission needs,” Wang wrote in the product’s announcement.
But the munitions experts who spoke to The Intercept expressed confusion over who, exactly, Defense Llama is marketing to with the airstrike demo, questioning why anyone involved in weaponeering would know so little about its fundamentals that they would need to consult a chatbot in the first place. “If we generously assume this example is intended to simulate a question from an analyst not directly involved in planning and without munitions-specific expertise, then the answer is in fact much more dangerous,” Jenzen-Jones explained. “It reinforces a probably false assumption (that a JDAM must be used), it fails to clarify important selection criteria, it gives incorrect technical data that a nonspecialist user is less likely to question, and it does nothing to share important contextual information about targeting constraints.”
“It gives incorrect technical data that a nonspecialist user is less likely to question.”
Bryant agreed. “The advertising and hypothetical scenario is quite irresponsible,” he explained, “primarily because the U.S. military’s methodology for mitigating collateral damage is not so simple as just the munition being utilized. That is one factor of many.” Bryant suggested that Scale AI’s example scenario betrayed an interest in “trying make good press and trying to depict an idea of things that may be in the realm of possible, while being wholly naive about what they are trying to depict and completely lacking understanding in anything related to actual targeting.”
Turning to an LLM for airstrike planning also means sidestepping the typical human-based process and the responsibility that entails. Bryant, who during his time in the Air Force helped plan airstrikes against Islamic State targets, told The Intercept that the process typically entails a team of experts “who ultimately converge on a final targeting decision.”
Jessica Dorsey, a professor at Utrecht University School of Law and scholar of automated warfare methods, said consulting Defense Llama seems to entirely circumvent the ostensible legal obligations military planners are supposed to be held to. “The reductionist/simplistic and almost [amateurish] approach indicated by the example is quite dangerous,” she said. “Just deploying a GBU/JDAM does not mean there will be less civilian harm. It’s a 500 to 2,000-pound bomb after all.”
